| 后台-系统设置-扩展变量-手机广告位-内容正文顶部 |
切问学术:面向5亿级论文库的科研知识图谱与自动化工作流平台
背景:当文献规模越过人脑筛选的临界值
科研工作中有一条隐性成本曲线——文献总量每增加一个数量级,人工初筛的时间消耗呈超线性增长。当前公开可获取的学术内容已突破数亿篇量级,研究者面临的问题不再是“找不到”,而是找到的成本过高、筛不准、连不上。
切问学术(QieWen Scholar)的切入路径是:不以“更大更好的搜索引擎”为目标,而是将 5 亿篇论文索引库 + 1.2 亿篇 OA 全文资源组织为可计算、可遍历、可追溯的科研知识图谱,再叠加以自然语言理解为入口的 AI 能力层,把研究工作流从“人工串联工具”推进到“端到端自动化闭环”。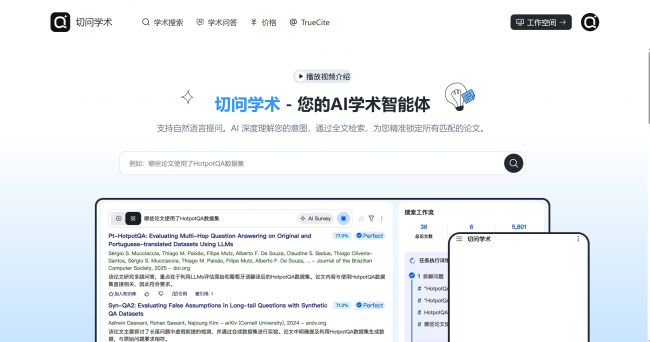
一、学术搜索(Scholar Search):用自然语言意图取代关键词猜谜
1.1 什么是“深度 AI 文献检索”?
传统检索系统的本质矛盾是:用户输入关键词 → 系统做字符串匹配 → 用户再从几百条结果里肉眼筛。这要求用户事先知道用什么词、用什么同义词、用什么布尔逻辑——相当于把“检索词构造”这件事的智力负担转嫁给了研究者。
切问学术的 学术搜索 把这一环节定义为一个 NLU(自然语言理解)→ 全文匹配 → 重排序 的管道:
• 入口变化:你不再需要写 (transformer AND vision) NOT survey,而是直接输入一句描述意图的话——系统负责拆解出隐含的研究对象、方法约束和时间范围。 • 数据底座:在 5 亿篇论文的元数据 + 全文索引上做深度匹配(含 DOI、作者、机构、发表时间、引用关系等多维字段),覆盖范围从 CS/AI 到材料、医学、工程等主流学科。 • 可量化指标:系统标称 检索准确率 95%,幻觉率趋于 0——关键不在于模型“生成得好看”,而在于每一条返回结果都能落回到真实存在的论文记录上。 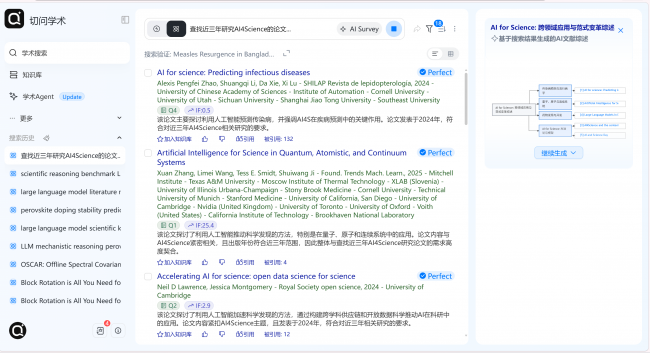
1.2 差异化能力(附应用场景)
① 快速浓缩:千中选二十
例如:某材料方向研究者拿到一组初步检索结果约 1,000 条,逐一打开摘要估算需要 3–5 个小时。切问学术在约 5 分钟内完成自动化过滤(依据:发表轨迹、引用活跃度、主题嵌入相似度、方法关键词簇),输出 20 篇高相关度候选论文,并附一段判定摘要说明“为什么这 20 篇进入短名单”。
这意味着初筛环节的时间从“半天”压到“泡一杯咖啡的功夫”,而且研究者仍然握有终否决权。
② 知识还原:模糊记忆 → 定位源头
例如:你只记得“去年好像有一篇关于对比学习在图网络上做的,实验部分用了三个化学数据集,重要作者姓氏像 Chen 但不是那篇公认的 SimCLR”——用关键词几乎拼不出这样的条件组合。学术搜索允许你把这段话直接贴进去,系统在 5 亿索引中按语义嵌入 + 结构化字段联合打分,把命中结果拉回来,并标出匹配到了哪些线索(时间窗口、数据集名、方法族谱)。
这条路径的价值在于:把“记得看过但找不到”的认知损耗趋近于零。
③ 跨学科冷启动
例如:一位做控制的老师突然需要摸一下“神经符号回归”这个方向的奠基性工作和近期变体。搜索入口同样是一句话意图,系统从引用图谱里把该方向的根节点论文(高被引早期工作)和近两年活跃分支一起拉出来,形成一个可展开的树形阅读清单——省掉“先花两周读教科书再找论文”的传统路径。
二、AI 综述(AI Survey):从“读完一堆再写”变成“先看到骨架再填充”
2.1 痛点到底卡在哪?
综述的真正难点通常不是“收集不到文献”,而是:
1. 不知道这个领域怎么分叉(哪些是主线、哪些是旁支、哪些是死胡同);
2. 不知道哪些论文是同一技术路线的不同版本;
3. 写出来容易变成罗列,而不是结构化的认知地图。
2.2 切问学术的做法:Taxonomy + 演进路径 + 可导出文本
AI 综述模块的主要产出是三层:
| 层级 | 内容 | 对研究者的用处 |
| 领域分类体系(Taxonomy) | 自动把该主题的论文集划分成若干技术子树,并命名每个子树的语义标签 | 一眼看清“这个领域到底有几条路线” |
| 演进路径可视化 | 沿引用链 + 时间轴标注各子树的起源节点、关键跃迁点和近期分化 | 回答“这条路从哪来、现在卷到哪了” |
| 结构化综述草稿 | 按 Taxonomy 组织成可编辑的长文/提纲,每节附标志文献引用 | 开题报告/引言部分的底稿不再从零起笔 |
例如:输入调研命题 “基于扩散模型的三维形状生成方法”,系统先拉取相关论文簇(依靠 5 亿索引 + 1.2 亿 OA 全文的覆盖),再按方法学维度分出“基于点云”“基于隐式场”“基于多视图”等子树,标注每条路的标志作与关键改进点,输出一份带参考文献骨架的综述草稿(支持 Word / Markdown 导出)。研究者后续的工作从“写完一篇综述”降级为“审改一份已有骨架的草稿”——量级差异。
三、知识库(Library):把 PDF 堆积变成可检索的团队资产
3.1 传统文献管理的天花板
Zotero / Mendeley 等工具解决了“收集 + 引用格式化”的问题,但没有解决“我在半年前下过一篇相关论文,现在想不起来文件名、文件夹或标题,但记得里面有个公式用了 Dirichlet 先验”这种检索需求。
3.2 切问学术知识库的两层升级
• 结构化入库:本地 PDF 一键上传后,系统抽取标题、作者、摘要、图表锚点、章节结构,归入可多端同步的个人 / 团队空间——本质是把非结构化的文件堆转化为带元数据的文献记录。 • 跨文档全文语义检索:检索不再限于文件名或手工打的 tag,而是在文档内部语义层做匹配,并给出命中的上下文片段,让你确认“就是这篇”。
例如:实验室新成员接手“多模态对齐损失函数”的调研,不必从零搜 PubMed / arXiv,而是先进团队共享库,用一句自然语言查 “我们之前存过哪些用了 InfoNCE 变体的?”,系统跨全部入库 PDF 给出命中片段与所在章节,新人 30 分钟内完成存量资产的吸收,而不是花三天重复下载。
四、学术Q&A(Scholar Q&A):以文献为证据链的对话引擎
⚠️ 说明:此模块即产品资料中的“学术Q&A”能力,为避免歧义此处以功能描述称 学术探究引擎——其本质不是闲聊式对话,而是受文献约束的Q&A。
4.1 关键约束:答案必须可被验证
学术场景下较大的风险不是“答不出来”,而是“看起来很有道理但编造了出处”。切问学术对这个模块的设计底线是:
• 所有输出论点 附带来源标注(对应到具体论文 / 页码 / 引用句段); • 区分“来自 5 亿级公域索引的全局知识”与“来自你私有库的局部知识”两种置信域。
4.2 典型用法
例如(硬核阅读):上传一篇含大量张量符号的预印本,框选一段推导问:“这段从式(3)到式(4)做了什么近似假设?”——系统提取上下文公式与相邻文本,给出逐步拆解,并用原文语句佐证每一步推断。
例如(横向对比):同时选中三篇关于同一任务的 SOTA 方法,提问:“这三篇在用到的数据集划分、评价指度和训练超参上有哪些不一致的地方?”——系统逐篇提取方法节 + 实验节的关键条目,排成对照表,省去人工交叉比对。
五、科研智能体(Scholar Agent / “科研龙虾”):模块化拼装的自动化工作流
5.1 为什么需要“智能体”而不是“更多按钮”?
科研任务的特征是:同一个大目标(写开题 / 做竞品技术摸底)在不同课题组里的执行步骤不一样——有人先做检索再做分类,有人先找综述再回溯引用,有人要先锁数据集再筛方法。
切问学术的 科研智能体提供的是一组可组合的原子能力:
| 可拼装模块 | 作用 |
| 选题建议器 | 给定大方向,输出待细分的研究问题和空白点 |
| 检索规划器 | 把一句意图展开为若干组检索策略 + 排除条件 |
| 文献筛选器 | 按相关性 / 新颖性 / 方法类型做多轮淘汰 |
| 综述组装器 | 把筛选结果映射到 Taxonomy 并生成章节草稿 |
| 实验环境提示器 | 给出复现所需的依赖线索(适配到具体论文声明) |
用户像搭积木一样拖合出自己的流水线——流程由研究者控制,执行由智能体代劳。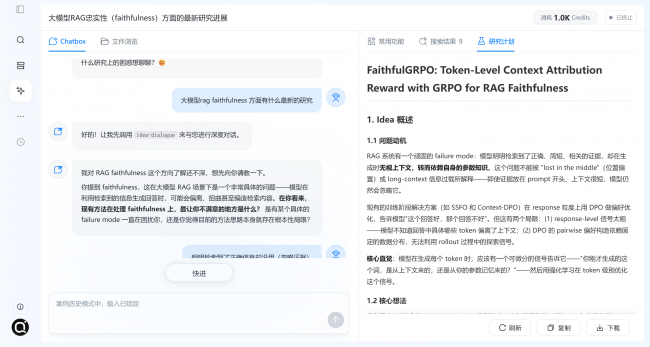
5.2 启发式对话:不止于执行命令
除了“做任务”,智能体还承担一层“苏格拉底式反问”的角色:
例如:你告诉智能体 “我想做‘轻量化 Transformer 在端侧时序预测上的应用’”,它会反问你一组结构化的澄清问题——端侧约束指推理延迟还是参数量?时序预测是 univariate 还是 multivariate?已有调研里你是否排除了纯 RNN 类基线?——这些问题本身就是在逼你把题目想清楚,避免开题后才发现边界没定义好。
六、AI 辅助阅读(AI-Assisted Reading):消除“读—译—抄—排”的中断链
6.1 沉浸式阅读层
辅助阅读模块围绕一个原则设计:研究者应该停留在论文的逻辑流里,而不是反复跳出到翻译器、手写笔记和 LaTeX 手工敲公式中。
• 多维翻译交互:全文翻译与划词解释并存——前者用于快速扫读,后者用于当你只需要某个术语或某一段落的确切含义时不破坏版面节奏。 • 批注层:支持荧光笔高亮 + 墨迹批注,贴合“纸质式深度阅读”的习惯心智模型。
6.2 转录提效:公式/表格 → LaTeX
这是实测中能节省机械劳动的部分——
例如:你在读一篇方法学论文,第 7 页有一个三行的损失函数和两个对齐条件的分段定义。传统做法是:盯着 PDF → 手动在 LaTeX 里 frac sum mathbb{I}敲十分钟。切问学术的 LaTeX 智能提取直接识别该区域,输出可用 LaTeX 代码块,复制到你的 Overleaf 里只需微调括号层级。
对表格同理:识别二维表结构 → 输出 tabular环境代码,含合并单元格与对齐规则——把“搬运数据”从手工活降级为“复核一遍”。
七、AI 订阅源与趋势(AI Feeds & Trends):把信息流从噪声变信号
7.1 问题定义
每天新增预印本以千计,RSS 和邮件提醒的失效原因是没有语义过滤器——它们只知道“你关注了某 ArXiv 类别”,但不知道你实际上只在意“带对比学习的医疗影像”还是“Transformer 替代架构”。
7.2 切问学术的做法:检索画像驱动的推送
• 专属科研晨报:系统依据你建过的检索、读过的高亮段落、存入知识库的标签,聚合出一份每日 / 每周摘要——每条新论文附一句“它跟你上次查的什么问题有关”。 • 爆款早期捕获:在 1.2 亿 OA 全文 + 主流索引源的更新流中,监控引用增速异常、作者网络跃迁(例如某冷门方向的论文突然被两个活跃大组同时引用)——这类信号往往早于“正式成为热点” 3–6 个月。
例如:你过去两周频繁检索过 segment anything 在遥感影像上的微调策略,订阅系统会在晨报里把新出的三篇相关预印本前置,并标注“其中 #2 的方法部分与你库里存的 Li et al. 2025 的 backbone 设定一致,可直接对照”。
总结:数据规模是地基,自动化闭环才是建筑
| 层级 | 切问学术的投入 |
| 数据地基 | 5 亿篇论文索引 · 1.2 亿篇 OA 全文 · 引用关系与作者-机构网络 |
| 理解层 | 自然语言意图解析 · 全文语义匹配 · 领域 Taxonomy 自动生成 |
| 执行层 | 智能体工作流拼装 · 跨公域/私域的证据链对话 · 千→二十级筛选 |
| 产出层 | 综述草稿 · 科研晨报 · LaTeX 转录 · 团队知识资产沉淀 |
切问学术的定位不是替研究者“想出答案”,而是把检索、过滤、整理、转录、追踪这些确定性但高消耗的环节接管过来,让人的脑力回到假设构建、方法设计和判断取舍上——也就是科研里真正不可替代的那部分。
| 后台-系统设置-扩展变量-手机广告位-内容正文底部 |







